Interactive Text to Image
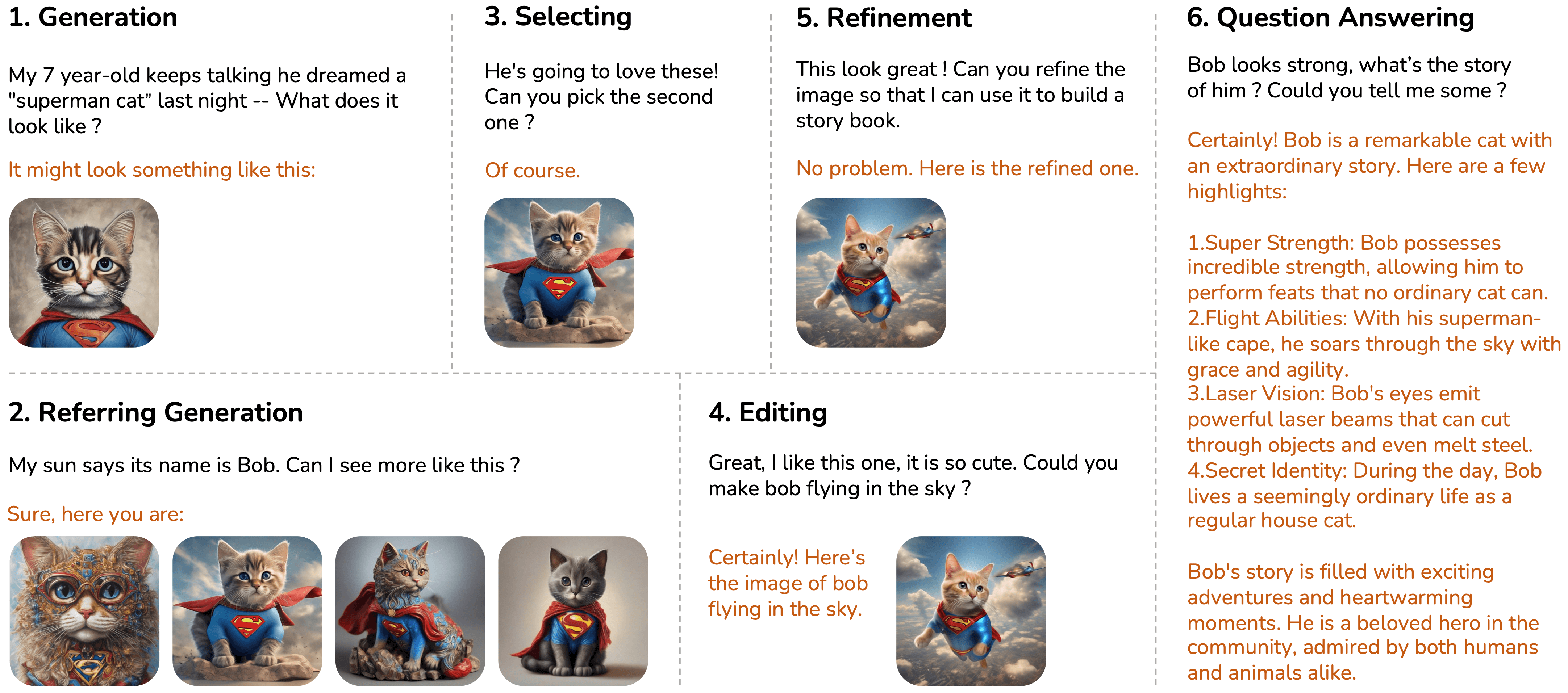
We introduce a new task - interactive text to image (iT2I), where people can interact with LLM for inter- leaved high-quality image generation/edit/refinement and question answering with stronger images and text correspondences using natural language.

Types of Interactions
There are various instructions that could be found in an iT2I system, such as generation, editing, se- lecting, and refinement.
Mini DALL•E 3
we present a simple approach that augments LLMs for iT2I with prompting techniques and off-the-shelf T2I models.
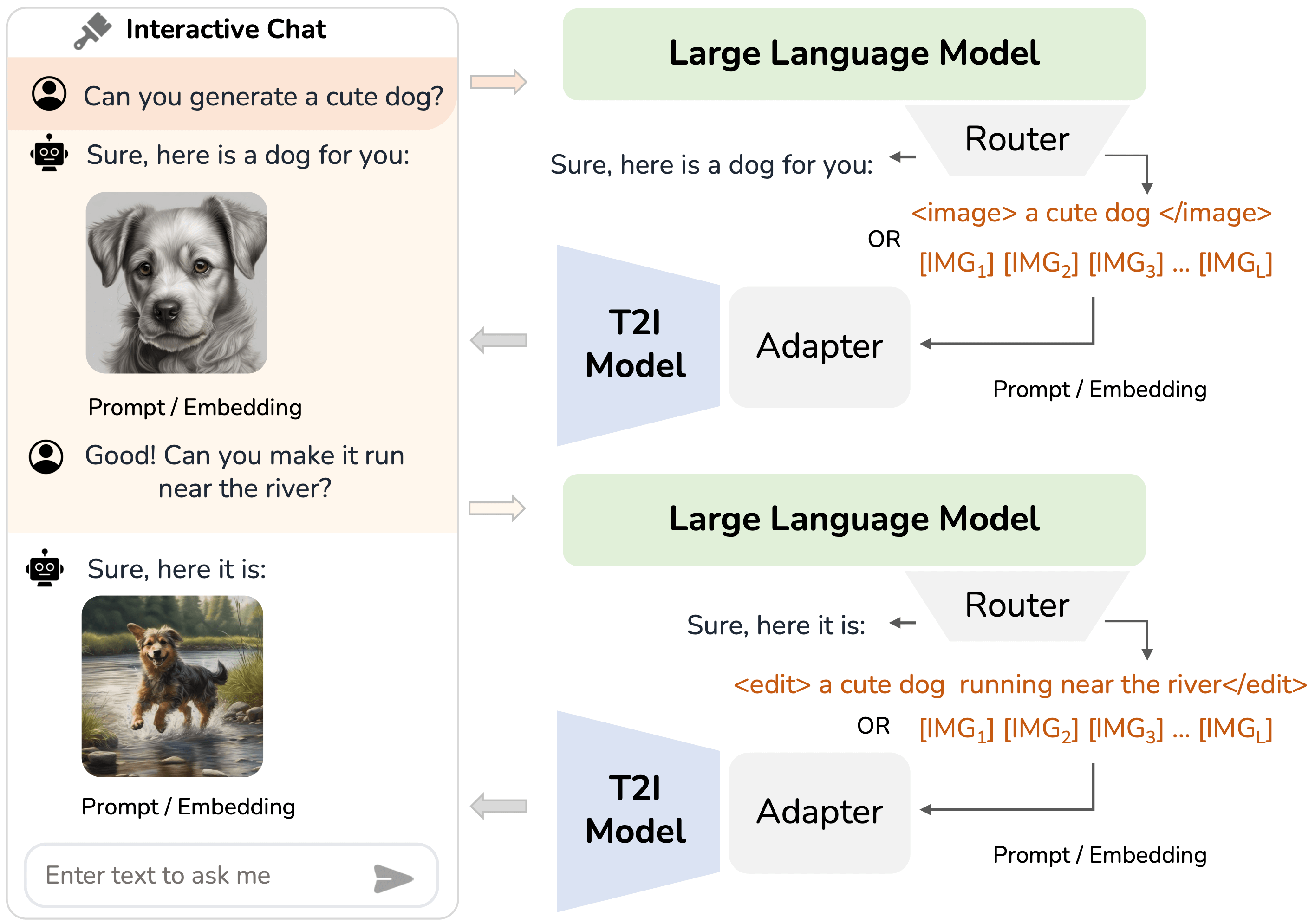
Results

Related Links
You may refer to related work that serves as foundations for our framework and code repository, Stable Diffusion XL, NExT-GPT, DALL•E 3, ChatGPT, and IP-Adapter.
BibTeX
@misc{minidalle3,
author={Lai, Zeqiang and Zhu, Xizhou and Dai, Jifeng and Qiao, Yu and Wang, Wenhai},
title={Mini-DALLE3: Interactive Text to Image by Prompting Large Language Models},
year={2023},
url={https://github.com/Zeqiang-Lai/Mini-DALLE3},
}